
拖延症终于更了…这篇文章 25 年春节前首发在我的公众号,后来又发在了知乎。那时候关于 DeepSeek v3 量化的系统性解读还不算多,这篇算是比较早做分享的,后来也意外收获了一些关注。
DeepSeek-V3 横空出世,不仅效果惊人,训练和推理成本也极低。
一个重要的原因就是采用了 FP8 进行训练和推理。
今天我们来一起探究其中的原理:
Group/Block-wise 量化
分块量化(Block-wise Quantization),也称为分组量化(Per-group Quantization),是一种细粒度量化方法。
特征异常值是指在特征分布中远离大部分数据的极端值。这些异常值对量化尤其具有挑战性,因为如果使用全局的量化参数(例如最大值),则这些异常值可能会导致大部分数据的量化精度下降。
细粒度量化的核心思想是使用更精细的量化粒度,即对输入和权重的不同部分使用不同的缩放因子。这样可以更好地适应数据的局部特征,减少异常值的影响。

分块量化示意
分块量化将张量分割成更小的块或组,并为每个块分配独立的量化参数(缩放因子 s 和零点 z)。
如上图所示,矩阵被分割成多个小块,每个小块使用不同的颜色进行标注,对应不同的量化参数。
- 优点:提供了对量化过程更精细的控制,通常会在模型精度和计算效率方面带来更好的性能。通过调整块的大小,可以在精度和效率之间进行灵活的权衡。相比逐张量量化,分块量化能够更好地适应张量内部数据分布的变化,减少量化误差;相比逐通道量化,分块量化可以减少需要存储的量化参数数量,从而降低存储开销。
- 缺点:需要合理划分组别,增加了量化策略的设计复杂性,而且分块量化对硬件不友好,计算效率低。
总之,Block-wise 量化是对矩阵分组,每一组有独立的量化参数,可以更好地控制精度损失。
DeepSeek-V3 的配置
首先看 DeepSeek-V3-FP8 版本的模型配置:
1 | "quantization_config": { |
量化精度:FP8 (E4M3)
量化粒度:
- 权重:block-wise 量化,shape 是 [128, 128],静态离线量化
- 激活:per-token-group 量化,动态在线量化
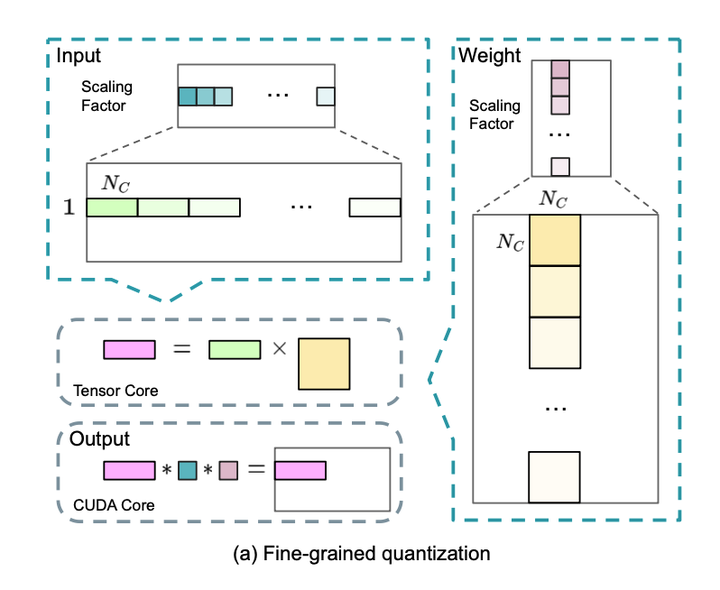
(1) 对于激活值,我们以 1x128 的组为基础对元素进行分组和缩放(每个 token 每 128 个通道); (2) 对于权重,我们以 128x128 的块为基础对元素进行分组和缩放(每 128 个输入通道每 128 个输出通道)。
结合上图我们来看下如何对权重和激活值进行量化:
权重量化(block-wise)
假设权重 B 的shape为: [hidden_dim, out_dim]
1.分块方式:
- 在hidden_dim维度上每128个输入特征一组
- 在out_dim维度上每128个输出特征一组
2.量化缩放因子(scales):
- Bs 的shape: [hidden_dim//128, out_dim//128]
- 每个权重块使用独立的scale
- 静态量化:权重量化是离线预计算好的
下面给出一个简化的 PyTorch 实现,展示 block-wise 的 reshape/转置/还原流程:
1 |
|
激活量化(per-token-group)
假设激活A输入的shape为: [batch_size x seq_len, hidden_dim]
1.分块方式:
- 对于每一个token,在hidden_dim维度上每128个通道的激活值分为一组,并为这一组计算一个单独的缩放因子。
2.量化缩放因子:
- As的shape: [batch_size x seq_len, hidden_dim//128]
- 每个块使用独立的scale进行量化
- 动态量化:在推理过程中,实时对激活进行量化
- 不对token维度分块
1 |
|
FP8-GEMM 工程实现
下面主要讨论 FP8 GEMM 的工程实现。
理解了上面的权重和激活量化原理,那么下面来看如何进行两个 FP8 量化矩阵的乘法运算。
经过量化,我们得到了下面参数:
1 | // inputs |
下面是 DeepSeek-V3 报告里对 FP8-GEMM 的 CUDA 层面计算流程解释:
GPU 计算流程
背景:
- 下溢和精度损失: 使用 FP8 等低精度格式进行 GEMM 运算时,中间结果的累加容易出现下溢,导致精度损失。传统的做法是使用 FP32 进行累加,以保持精度。
下溢指的是计算结果的绝对值非常小,小于浮点数所能表示的最小正数(非零)。换句话说,计算结果太接近于零,以至于计算机无法用当前的浮点数格式精确地表示它,通常会被近似为零。
DeepSeek-V3 的方案:
所有 FP8 张量都采用 E4M3 格式(4 位指数和 3 位尾数),以获得更高的精度。

FP8 格式
计算过程:
以 N_c = 128 个元素为间隔,将 MMA 的结果转移到 CUDA Cores 进行高精度累加。
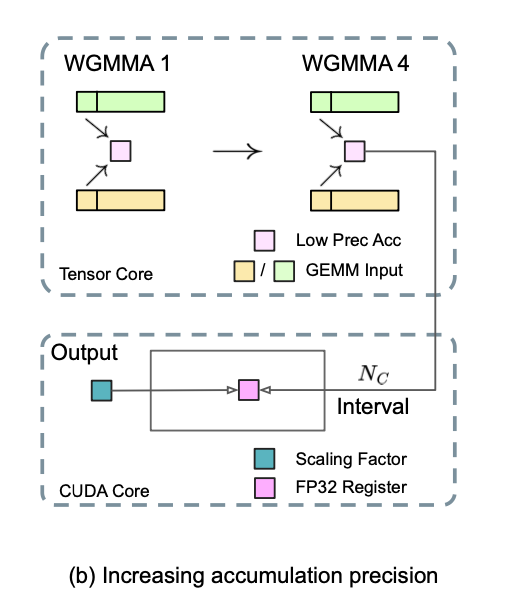
GPU 计算流程
每当 Tensor Core 累加了 128 个 FP8 结果后,就会将这些结果转换(或缩放)到 FP32 精度,然后在 CUDA Cores 的 FP32 寄存器中进行累加。
计算流程:
- Tensor Core 以 FP8 精度高效地执行大量的矩阵乘法和累加(MMA)操作,使用低精度累加器存储中间结果。
- 每累加 128 个元素(N_c = 128),就将这些 FP8 累加结果转换到 FP32 精度。
- 在 CUDA Cores 的 FP32 寄存器中进行高精度的累加,最终结果经过 Scaling Factor 缩放,也就是反量化。
- 重复步骤 1-3,直到完成所有的矩阵乘法和累加操作。
Python 原生实现
核心代码:
1 | def native_w8a8_block_fp8_matmul(A, B, As, Bs, block_size, output_dtype=torch.float16): |
可以结合上面对矩阵乘法的注释来理解分块矩阵乘法的过程:
进行矩阵乘法的时候,先对矩阵 A 和 B 依照各自的量化粒度分块,在分块的粒度上进行矩阵乘法运算,然后再乘以量化因子进行反量化,得到分块的 FP32 浮点结果。
Triton 实现
代码参考 sglang 中的实现:
1. 函数接口:
1 | def w8a8_block_fp8_matmul( |
2. Triton 算子配置
1 | # 尝试加载之前通过 tuning 方式获得的最佳配置信息。 |
可以通过对 Triton 算子进行 tuning 来得到最优的 kernel 配置,接着调用 Triton 算子。
3. Triton 算子实现
我觉得 Triton 的代码介于 PyTorch 和 CUDA 代码之间,它提供了一种比手写 CUDA 算子更高层次的抽象,方便开发。
核心计算流程如下,注意累加器 accumulator 是 float32 精度的。
1 |
|
CUTLASS 实现
先了解一下几种量化缩放的术语(和量化粒度有关):
- 张量级缩放(Tensorwise Scaling): 每个张量使用单个缩放因子,在尾声(epilogue)中应用。
- 行级缩放(Rowwise Scaling): 使用一个行向量进行缩放,对于操作数 A 的维度为 M x 1,对于操作数 B 的维度为 1 x N,避免沿归约维度进行缩放。这也可以在尾声中使用 EpilogueVisitorTree 来处理。
- 分块缩放(Blockwise Scaling): 引入一个 2D 缩放张量,每个 CTA 块分配一个缩放值。由于此缩放涉及归约维度 (M, N, K),因此必须在主循环中应用,这会影响性能。
- 分组缩放(Groupwise Scaling): 使用一个 2D 缩放张量,每个 CTA 块有多个缩放值。缩放粒度独立于 CTA 块配置,为将来的实现提供了更大的灵活性。
关于 FP8 block-wise 量化有先后两个 PR,第一个 PR 先支持了 Blockwise Scaling,第二个 PR 在第一个的基础上支持了 Groupwise Scaling,下面依次介绍。
分块缩放
第一个 PR [1] 实现了 CUTLASS F8 GEMM 的分块缩放(Blockwise Scaling),通过共享内存暂存缩放张量,并为将来支持分组缩放做准备。

上面这张图表示了分块缩放:
- CTA Tile (128x128x128): 这表示一个 CUDA 线程块(CTA)处理的数据块的大小。在这个例子中,每个 CTA 处理一个 128x128 的输出块,其中 K 维度(归约维度)的大小也是 128。这个 128x128x128 是逻辑上的,实际的计算可能根据 warp size 进一步划分。
- A (640x512): 输入矩阵 A 的维度是 640x512 (M x K)。
- B (512x384): 输入矩阵 B 的维度是 512x384 (K x N)。
- Scale A (5x4): A 的缩放因子矩阵,维度是 5x4。这里的 5 对应 M 维度被划分成的块数(640 / 128 = 5,向上取整),4 对应 K 维度被划分成的块数(512 / 128 = 4)。每个元素对应 A 的一个 128x128 的块的缩放因子。
- Scale B (4x3): B 的缩放因子矩阵,维度是 4x3。这里的 4 对应 K 维度被划分成的块数(512 / 128 = 4),3 对应 N 维度被划分成的块数(384 / 128 = 3)。每个元素对应 B 的一个 128x128 的块的缩放因子。
- 输出矩阵 C (绿色部分): 输出矩阵 C 的维度是 640x384 (M x N)。它被划分成若干个 128x128 的块,每个块由一个 CTA 计算。
分组缩放
第二个 PR [2] 在第一个 PR(添加了分块缩放策略)的基础上,进一步添加了针对 A 张量 M 维度的分组缩放策略。
沿 M 维度的缩放粒度与 CTA 块配置无关,但是,沿 N 和 K 维度的缩放粒度仍然是分块的(即每个 CTA 块一个缩放值)。
所以到了这一步,基于这个 PR 我们才能实现与前面 PyTorch 和 Triton 代码功能相同的 kernel。
作者具体使用了 CUTLASS 3.0 新 API 在 Hopper 架构上进行分组缩放 FP8 GEMM 运算。
- NVIDIA Hopper 架构引入了新的 Tensor Core 指令集(GMMA),比 Ampere 的 Tensor Core 指令更高效。
- Hopper 架构包含新的 Tensor Memory Accelerator (TMA) 单元,可以在全局内存和共享内存之间高效地传输大型数据块。TMA 还支持线程块之间异步拷贝。
- 使用了 Warp Specialized 内核设计。
CUTLASS 中 FP8 E4M3 使用 cutlass::float_e4m3_t 来表示,代码比较长,在这里不详细分析了。
作者在 PR 里给的 example 只是告诉了如何使用这个 GEMM,基于特定场景还需要做定制化开发优化。
如果要基于 CUTLASS 3.0 开发 kernel,有两个利器可以使用:
- CuTe:大大简化了 CUTLASS 中复杂数据布局和线程组织的管理
- EVT:用于在 GEMM 的尾声阶段融合各种后处理操作的框架,以提高性能和效率。参考论文:EVT: Accelerating Deep Learning Training with Epilogue Visitor Tree
本文介绍了 FP8 block-wise 量化的原理以及推理的工程实现,很多时候想到一个好的量化算法并不难,难的是和硬件特性结合起来,在保持精度的前提下发挥量化的最大性能。
DeepSeek-V3 这类 MoE 模型在推理中,有需要用到 Grouped GEMM 的场景,后面有时间分析下这一块。
随着大模型应用日渐普遍,大模型的训练和推理工程基础建设如火如荼,也涌出了很多 AI Infra 创业公司。
有人说 AI Infra 会是大模型时代的 CRUD,也有人说是大模型时代的土木。
无论如何 AI Infra 都会在大模型这波浪潮中扮演重要的角色。
参考资料
- Cutlass PR#1932: https://github.com/NVIDIA/cutlass/pull/1932
- Cutlass PR#2037: https://github.com/NVIDIA/cutlass/pull/2037
